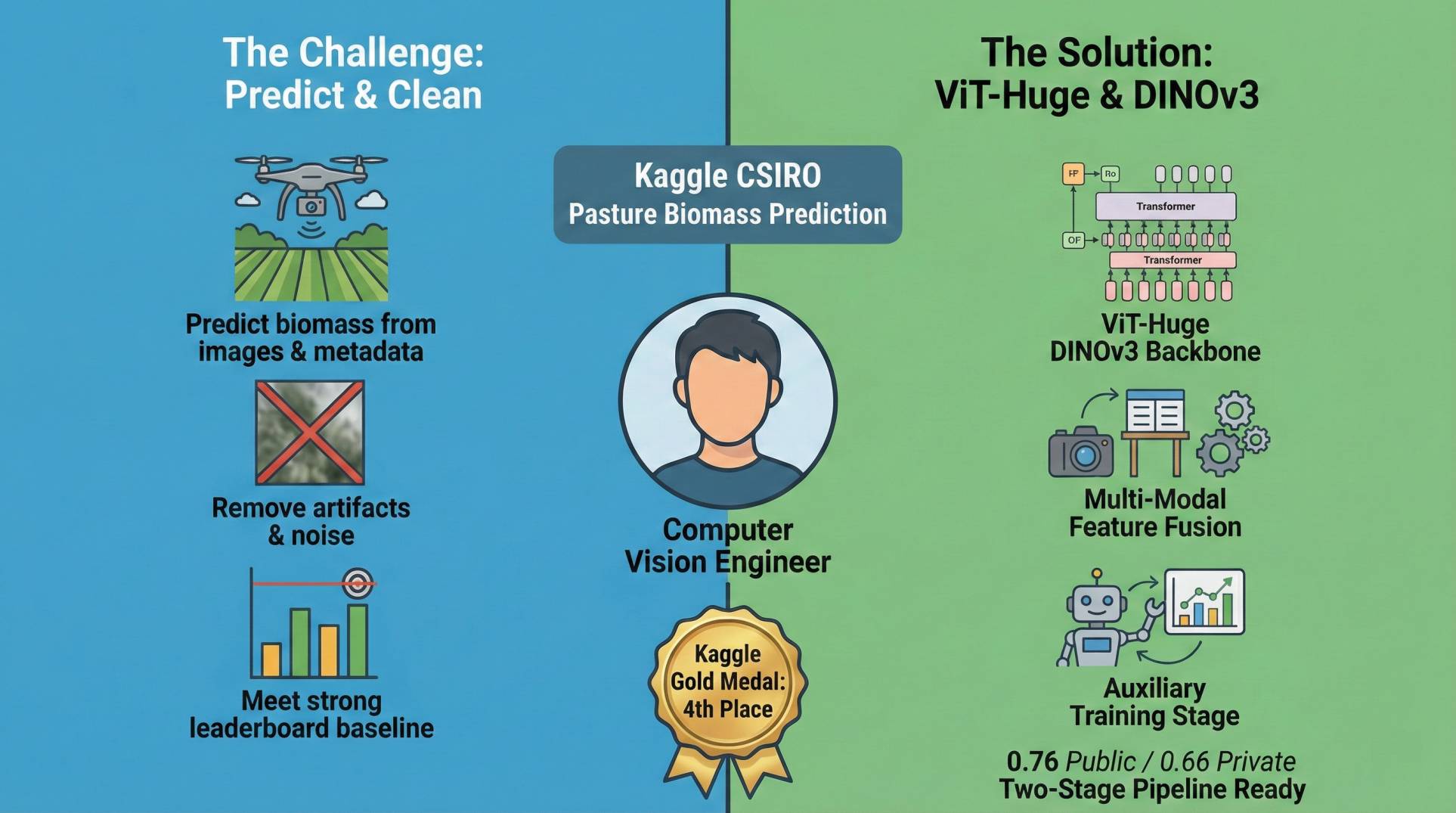
The Challenge
- Predict biomass from high-resolution pasture images plus NDVI and height metadata.
- Remove background artifacts and noise in the image set to avoid spurious signals.
- Meet a strong leaderboard baseline with limited compute and heavy models.
The Solution
- Built a ViT-Huge DINOv3 backbone with multi-modal feature fusion for images and tabular data.
- Introduced a manual cropping pipeline to eliminate cardboard background artifacts.
- Added an auxiliary training stage to predict NDVI and height from images for better feature learning.
Key Outcomes
- Placed 4th overall, earning a Gold Medal.
- Achieved 0.76 public and 0.66 private leaderboard scores after auxiliary training.
- Delivered a two-stage training pipeline ready for Kaggle-scale inference.
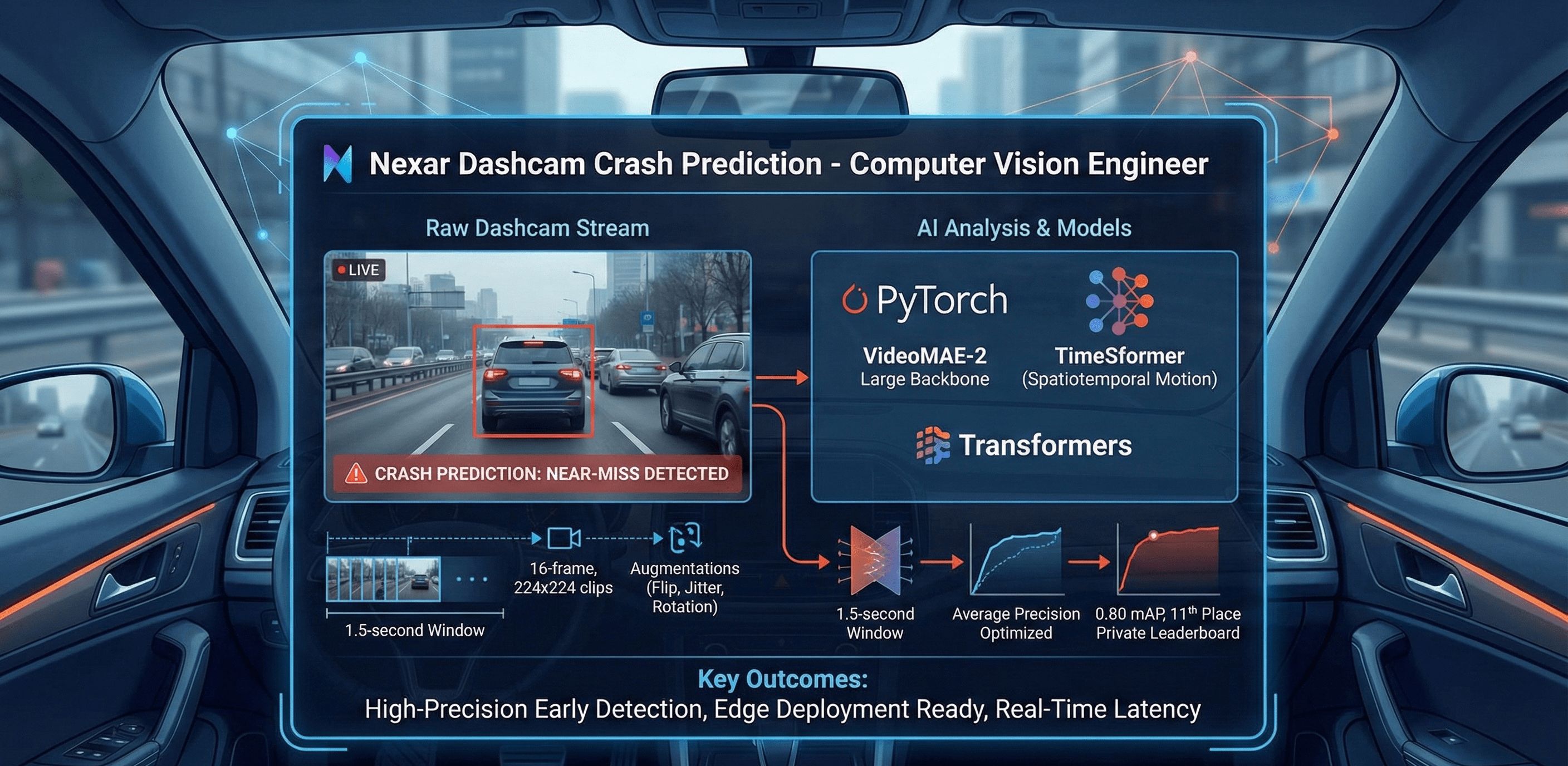
The Challenge
- Build a safety-critical model that flags collisions and near-misses from raw dashcam
streams in real time.
- Handle a heavily imbalanced dataset of 1,500 videos with nuanced temporal cues
inside a 1.5-second window.
- Differentiate normal traffic stops from sudden braking to minimize false alarms.
The Solution
- Fine-tuned VideoMAE-2 Large as the backbone for binary event classification.
- Preprocessed 16-frame, 224x224 clips with TimeSformer to capture spatiotemporal
motion signals.
- Applied strong augmentations (flip, color jitter, rotation) to combat overfitting on
scarce data.
- Trained with Hugging Face Trainer on dual T4s, optimizing Average Precision across
500ms, 1000ms, and 1500ms horizons.
Key Outcomes
- Placed 11th on the private leaderboard with 0.80 mAP.
- Delivered high-precision early accident detection suitable for edge deployment.
- Optimized batch inference to keep real-time latency in check.
The Challenge
- Automate detection of nuanced math misconceptions from free-form student
explanations.
- Control false positives where correct answers hide incorrect reasoning.
- Meet a strict 9-hour inference budget on limited T4/L4 compute.
The Solution
- Built a six-model ensemble spanning Qwen 2.5/3, Hunyuan 7B, and DeepSeekMath for
reasoning diversity.
- Used QLoRA (4-bit) and LoRA adapters to fine-tune up to 14B parameters on modest
hardware.
- Created a family-based weighted voting system combining probability sums, agreement
bonuses, and correctness filters.
- Ran domain-adaptive pretraining on math misconception corpora to align outputs with
pedagogy.
Key Outcomes
- Silver Medal - 45th globally with 0.947 MAP@3.
- Outperformed baseline BERT models while meeting the 9-hour runtime cap.
- Delivered a scalable ensemble pipeline for constrained inference budgets.
The Challenge
- Deliver accurate plagiarism detection without expensive proprietary APIs or large
models.
- Handle PDF ingestion and sentence-level semantic comparison for subtle paraphrasing.
- Prove that small language models can excel on focused downstream tasks.
The Solution
- Fine-tuned SmolLM2 (135M) into a binary classifier using the MIT Plagiarism dataset.
- Trained with AdamW and Cross-Entropy over three epochs with custom padding for
variable lengths.
- Built an end-to-end Streamlit app with PyMuPDF extraction feeding the inference
engine.
- Deployed the full stack on Hugging Face Spaces for instant, serverless access.
Key Outcomes
- Reached 96.20% accuracy and 0.96 F1 on 73k+ samples.
- Delivered a fast, low-cost alternative to billion-parameter solutions.
- Open-sourced the model and app under MIT for community use.
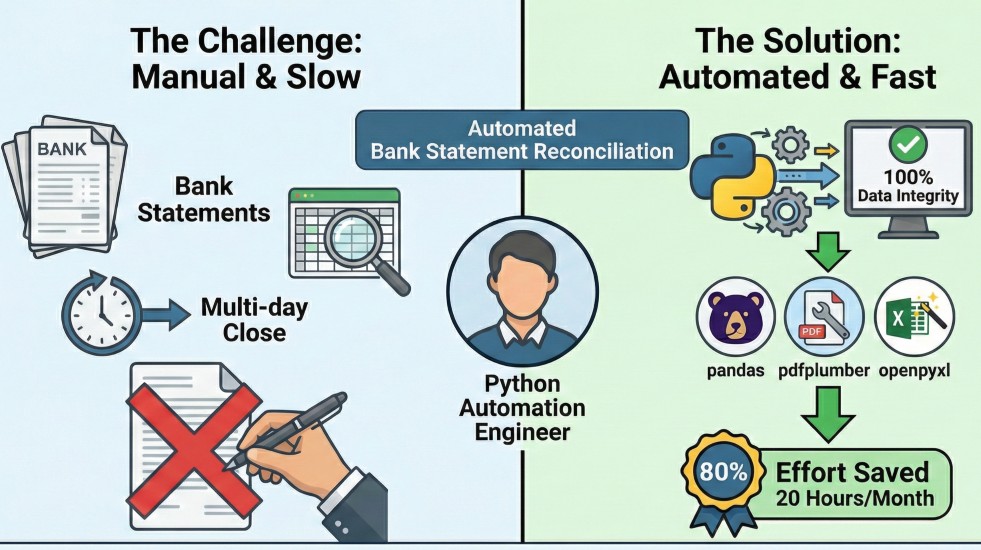
The Challenge
- Replace manual reconciliation of 1,000+ monthly transactions locked in PDFs and
Excel.
- Normalize inconsistent statement formats while avoiding human transcription errors.
- Compress a multi-day close process into minutes.
The Solution
- Extracted high-fidelity transaction data from PDFs via pdfplumber.
- Built a Pandas reconciliation engine matching by date, amount, and reference codes.
- Generated formatted Excel discrepancy reports automatically with OpenPyXL.
Key Outcomes
- Cut manual effort by 80%, saving about 20 hours per month.
- Achieved 5x faster processing with 100% data integrity.
- Flagged unmatched items instantly for finance review.
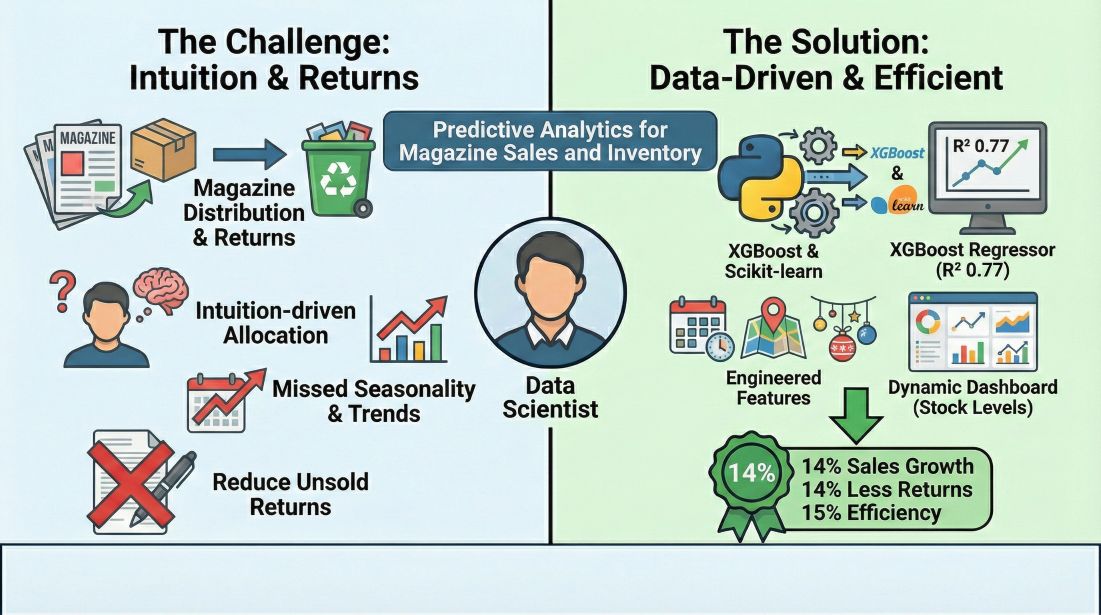
The Challenge
- Balance supply and demand for magazine distribution while reducing returns.
- Move from intuition-driven allocations to data-backed forecasts.
- Capture seasonality, regional demographics, and holiday effects in one model.
The Solution
- Trained an XGBoost regressor that hit R^2 of 0.77 on validation.
- Engineered trend, seasonality, demographic, and holiday features for better signal.
- Built a dynamic dashboard recommending per-location stock levels.
Key Outcomes
- Drove 14% year-over-year sales growth by protecting high-demand areas.
- Reduced unsold returns by 14%, lowering logistics and print waste.
- Improved sales ops efficiency by 15%, freeing time for strategy.